本文介紹 arrow 提供的各種資料物件類型,並說明這些物件的結構。
arrow 套件提供幾種用於表示資料的物件類別。RecordBatch、Table 和 Dataset 物件是用於儲存表格資料的二維矩形資料結構。對於欄狀、一維資料,則提供 Array 和 ChunkedArray 類別。最後,Scalar 物件表示個別值。下表總結了這些物件,並說明如何使用 R6 類別物件建立新的實例,以及以更傳統的 R 風格提供相同功能的便利函數
| 維度 | 類別 | 如何建立實例 | 便利函數 |
|---|---|---|---|
| 0 | Scalar |
Scalar$create(value, type) |
|
| 1 | Array |
Array$create(vector, type) |
as_arrow_array(x) |
| 1 | ChunkedArray |
ChunkedArray$create(..., type) |
chunked_array(..., type) |
| 2 | RecordBatch |
RecordBatch$create(...) |
record_batch(...) |
| 2 | Table |
Table$create(...) |
arrow_table(...) |
| 2 | Dataset |
Dataset$create(sources, schema) |
open_dataset(sources, schema) |
稍後在本文中,我們將更詳細地研究這些物件。現在我們注意到,這些物件類別中的每一個都對應於底層 Arrow C++ 程式庫中同名的類別。
除了這些資料物件之外,arrow 還定義了以下類別來表示 metadata
Schema是Field物件的列表,用於描述表格資料物件的結構;其中Field指定字串名稱和DataType;以及DataType是一個控制值如何表示的屬性
這些 metadata 物件在確保資料正確表示方面發揮重要作用,所有三種表格資料物件類型(Record Batch、Table 和 Dataset)都包含用於表示 metadata 的明確 Schema 物件。若要深入瞭解這些 metadata 類別,請參閱metadata 文章。
Scalars
Scalar 物件只是一個可以是任何類型的單一值。它可能是整數、字串、時間戳記或 Arrow 支援的任何不同 DataType 物件。arrow R 套件的大多數使用者不太可能直接建立 Scalars,但如果需要,您可以透過呼叫 Scalar$create() 方法來完成
Scalar$create("hello")## Scalar
## helloArrays
Array 物件是 Scalar 值的有序集合。與 Scalars 一樣,大多數使用者不需要直接建立 Arrays,但如果需要,可以使用 Array$create() 方法來建立新的 Arrays
integer_array <- Array$create(c(1L, NA, 2L, 4L, 8L))
integer_array## Array
## <int32>
## [
## 1,
## null,
## 2,
## 4,
## 8
## ]string_array <- Array$create(c("hello", "amazing", "and", "cruel", "world"))
string_array## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]Array 可以使用方括號進行子集化,如下所示
string_array[4:5]## Array
## <string>
## [
## "cruel",
## "world"
## ]Arrays 是不可變的物件:一旦建立 Array,就無法修改或擴充它。
Chunked Arrays
實際上,arrow R 套件的大多數使用者可能會使用 Chunked Arrays 而不是簡單的 Arrays。在底層,Chunked Array 是一個或多個 Arrays 的集合,可以像索引單個 Array 一樣進行索引。Arrow 提供此功能的原因在資料物件佈局文章中進行了描述,但就目前而言,足以注意到 Chunked Arrays 在常規資料分析中的行為方式與 Arrays 類似。
為了說明,讓我們使用 chunked_array() 函數
chunked_string_array <- chunked_array(
string_array,
c("I", "love", "you")
)chunked_array() 函數只是對 ChunkedArray$create() 提供的功能的封裝。讓我們列印物件
chunked_string_array## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ],
## [
## "I",
## "love",
## "you"
## ]
## ]此輸出中的雙重括號旨在突顯 Chunked Arrays 是圍繞一個或多個 Arrays 的封裝器。然而,儘管 Chunked Array 由多個不同的 Arrays 組成,但可以像將它們首尾相連地佈置在單個「類似向量」的物件中一樣進行索引。如下所示
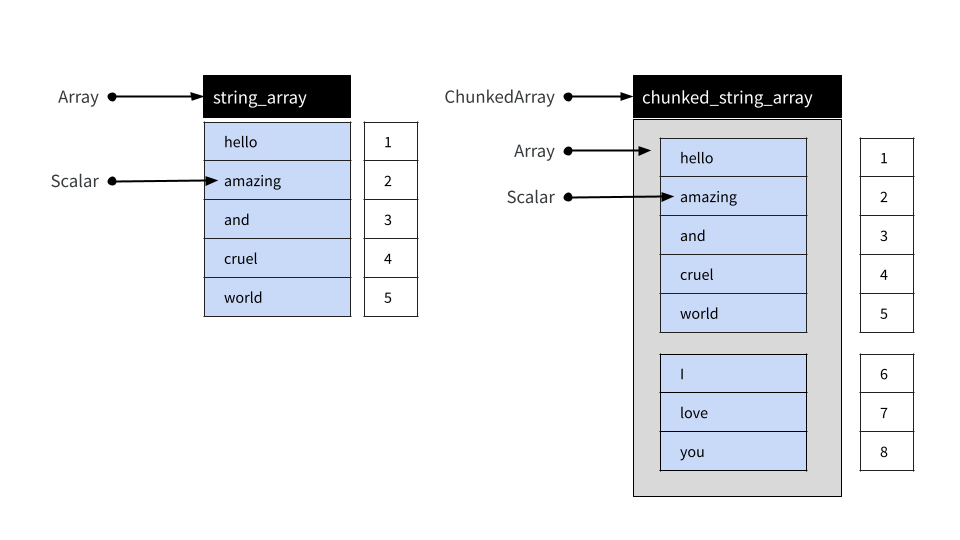
我們可以使用 chunked_string_array 來說明這一點
chunked_string_array[4:7]## ChunkedArray
## <string>
## [
## [
## "cruel",
## "world"
## ],
## [
## "I",
## "love"
## ]
## ]需要注意的重要一點是,「分塊」在語義上沒有意義。它僅是一個實作細節:使用者絕不應將塊視為有意義的單元。例如,將資料寫入磁碟通常會導致資料組織成不同的塊。同樣,包含分配給不同塊的相同值的兩個 Chunked Arrays 被視為等效。為了說明這一點,我們可以建立一個 Chunked Array,其中包含與 chunked_string_array[4:7] 相同的四個值,但組織成一個塊而不是分成兩個
cruel_world <- chunked_array(c("cruel", "world", "I", "love"))
cruel_world## ChunkedArray
## <string>
## [
## [
## "cruel",
## "world",
## "I",
## "love"
## ]
## ]使用 == 測試相等性會產生元素級比較,結果是一個新的由四個(布林類型)true 值組成的 Chunked Array
cruel_world == chunked_string_array[4:7]## ChunkedArray
## <bool>
## [
## [
## true,
## true,
## true,
## true
## ]
## ]簡而言之,目的是讓使用者與 Chunked Arrays 互動時,就好像它們是普通的一維資料結構一樣,而無需過多考慮底層的分塊排列。
Chunked Arrays 是可變的,在特定意義上:可以從 Chunked Array 中添加和移除 Arrays。
Record Batches
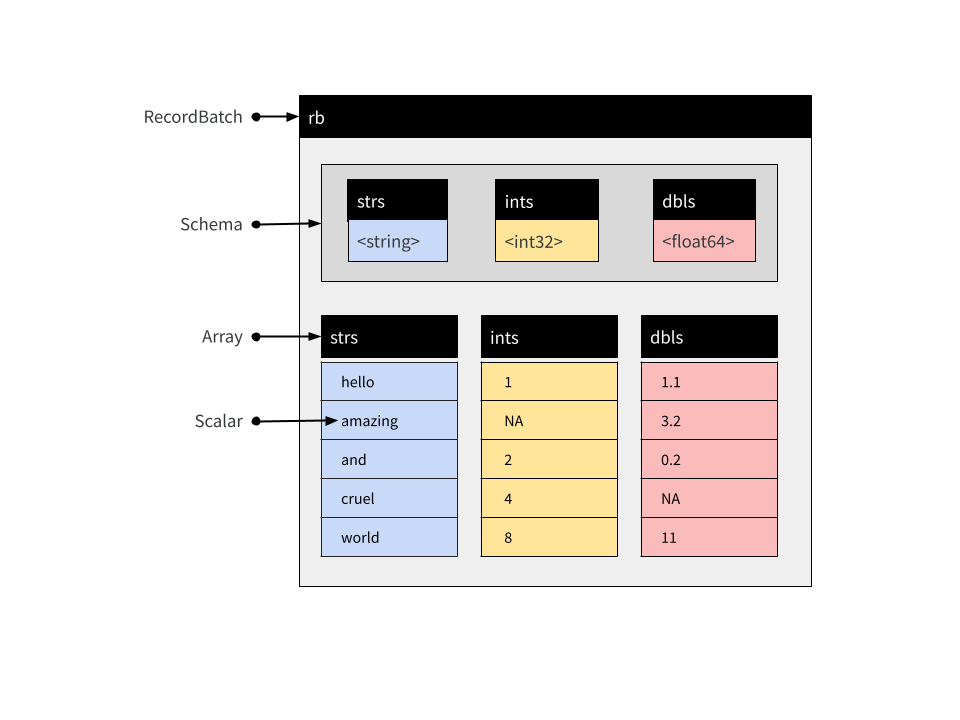
Record Batch 是一種表格資料結構,由具名 Arrays 和一個伴隨的 Schema 組成,該 Schema 指定與每個 Array 關聯的名稱和資料類型。Record Batches 是 Arrow 中資料交換的基本單元,但通常不用於資料分析。在分析上下文中,Tables 和 Datasets 通常更方便。
這些 Arrays 可以是不同的類型,但必須都具有相同的長度。每個 Array 都被稱為 Record Batch 的「欄位」或「列」。您可以使用 record_batch() 函數或使用 RecordBatch$create() 方法建立 Record Batch。這些函數很靈活,可以接受多種格式的輸入:您可以傳遞資料框、一個或多個具名向量、輸入流,甚至包含適當二進位資料的原始向量。例如
rb <- record_batch(
strs = string_array,
ints = integer_array,
dbls = c(1.1, 3.2, 0.2, NA, 11)
)
rb## RecordBatch
## 5 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>這是一個包含 5 列和 3 行的 Record Batch,其概念結構如下所示
arrow 套件為 Record Batch 物件提供 $ 方法,用於按名稱提取單個列
rb$strs## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]您可以使用雙重括號 [[ 按位置引用列。rb$ints array 是我們 Record Batch 中的第二列,因此我們可以使用它來提取
rb[[2]]## Array
## <int32>
## [
## 1,
## null,
## 2,
## 4,
## 8
## ]還有 [ 方法,允許您以與資料框相同的方式提取 record batch 的子集。命令 rb[1:3, 1:2] 提取前三列和前兩行
rb[1:3, 1:2]## RecordBatch
## 3 rows x 2 columns
## $strs <string>
## $ints <int32>Record Batches 無法串連:因為它們由 Arrays 組成,而 Arrays 是不可變的物件,所以一旦建立 Record Batch,就無法向其添加新列。
Tables
Table 由具名 Chunked Arrays 組成,就像 Record Batch 由具名 Arrays 組成一樣。與 Record Batches 類似,Tables 包含一個明確的 Schema,用於指定每個 Chunked Array 的名稱和資料類型。
您可以使用 $、[[ 和 [ 子集化 Tables,方式與 Record Batches 相同。與 Record Batches 不同,Tables 可以串連(因為它們由 Chunked Arrays 組成)。假設第二個 Record Batch 到達
new_rb <- record_batch(
strs = c("I", "love", "you"),
ints = c(5L, 0L, 0L),
dbls = c(7.1, -0.1, 2)
)不可能建立一個將 new_rb 中的資料附加到 rb 中的資料的 Record Batch,除非在記憶體中建立全新的物件。但是,使用 Tables,我們可以
df <- arrow_table(rb)
new_df <- arrow_table(new_rb)我們現在將資料集的兩個片段表示為 Tables。Table 和 Record Batch 之間的區別在於列都表示為 Chunked Arrays。原始 Record Batch 中的每個 Array 都是 Table 中相應 Chunked Array 中的一個塊
rb$strs## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]df$strs## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]
## ]它是相同的底層資料——實際上,兩者都引用了相同的不可變 Array——只是用新的、靈活的 Chunked Array 封裝器封裝。然而,正是這個封裝器使我們能夠串連 Tables
concat_tables(df, new_df)## Table
## 8 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>產生的物件在下面以示意圖方式顯示
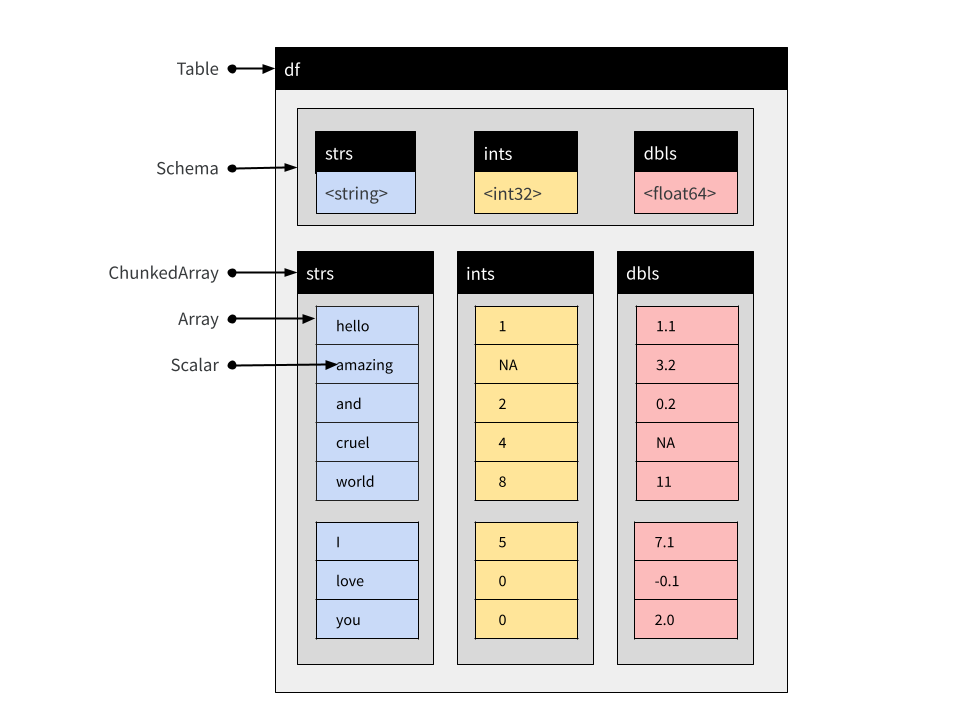
請注意,新 Table 中的 Chunked Arrays 保留了這種分塊結構,因為沒有移動任何原始 Arrays
df_both <- concat_tables(df, new_df)
df_both$strs## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ],
## [
## "I",
## "love",
## "you"
## ]
## ]Datasets
與 Record Batch 和 Table 物件一樣,Dataset 用於表示表格資料。在抽象層次上,Dataset 可以被視為由列和行組成的物件,並且與 Record Batches 和 Tables 一樣,它包含一個明確的 Schema,用於指定與每一列關聯的名稱和資料類型。
但是,Tables 和 Record Batches 是記憶體中明確表示的資料,而 Dataset 則不是。相反,Dataset 是一個抽象概念,它引用儲存在磁碟上一個或多個檔案中的資料。儲存在資料檔案中的值會以批次處理方式載入到記憶體中。載入僅在需要時發生,並且僅在針對資料執行查詢時發生。在這方面,Arrow Datasets 與 Arrow Tables 是非常不同類型的物件,但用於分析它們的 dplyr 命令本質上是相同的。在本節中,我們將討論 Datasets 的結構。如果您想瞭解有關分析 Datasets 的實務細節,請參閱分析多檔案資料集的文章。
磁碟上的資料檔案
簡而言之,Dataset 的磁碟結構只是一個資料檔案的集合,每個檔案儲存資料的一個子集。這些子集有時稱為「片段」,而分割程序有時稱為「分片」。按照慣例,這些檔案被組織成稱為 Hive 風格分割的資料夾結構:有關詳細資訊,請參閱 hive_partition()。
為了說明其工作原理,讓我們手動將多檔案資料集寫入磁碟,而無需使用任何 Arrow Dataset 功能來完成工作。我們將從三個小型資料框開始,每個資料框都包含我們要儲存的資料的一個子集
df_a <- data.frame(id = 1:5, value = rnorm(5), subset = "a")
df_b <- data.frame(id = 6:10, value = rnorm(5), subset = "b")
df_c <- data.frame(id = 11:15, value = rnorm(5), subset = "c")我們的意圖是將每個資料框儲存在單獨的資料檔案中。如您所見,這是一個結構化的分割:所有 subset = "a" 的資料都屬於一個檔案,所有 subset = "b" 的資料都屬於另一個檔案,所有 subset = "c" 的資料都屬於第三個檔案。
第一步是定義並建立一個資料夾,用於保存所有檔案
ds_dir <- "mini-dataset"
dir.create(ds_dir)下一步是手動建立 Hive 風格的資料夾結構
ds_dir_a <- file.path(ds_dir, "subset=a")
ds_dir_b <- file.path(ds_dir, "subset=b")
ds_dir_c <- file.path(ds_dir, "subset=c")
dir.create(ds_dir_a)
dir.create(ds_dir_b)
dir.create(ds_dir_c)請注意,我們以「key=value」格式命名了每個資料夾,該格式確切地描述了將寫入該資料夾的資料子集。這種命名結構是 Hive 風格分割的本質。
現在我們有了資料夾,我們將使用 write_parquet() 為三個子集中的每一個建立一個 parquet 檔案
write_parquet(df_a, file.path(ds_dir_a, "part-0.parquet"))
write_parquet(df_b, file.path(ds_dir_b, "part-0.parquet"))
write_parquet(df_c, file.path(ds_dir_c, "part-0.parquet"))如果我們願意,我們可以進一步細分資料集。如果我們願意,一個資料夾可以包含多個檔案(part-0.parquet、part-1.parquet 等)。同樣,完全沒有特別的理由以這種方式命名檔案 part-0.parquet:如果我們願意,可以將這些檔案稱為 subset-a.parquet、subset-b.parquet 和 subset-c.parquet。如果我們願意,我們可以寫入其他檔案格式,並且我們不一定必須使用 Hive 風格的資料夾。您可以透過閱讀 open_dataset() 的幫助文件來瞭解有關支援格式的更多資訊,並透過 help("Dataset", package = "arrow") 瞭解如何進行細粒度控制。
在任何情況下,我們都使用 Hive 風格分割建立了一個磁碟上的 parquet Dataset。我們的 Dataset 由以下檔案定義
list.files(ds_dir, recursive = TRUE)## [1] "subset=a/part-0.parquet" "subset=b/part-0.parquet"
## [3] "subset=c/part-0.parquet"為了驗證一切正常,讓我們使用 open_dataset() 開啟資料,並呼叫 glimpse() 來檢查其內容
ds <- open_dataset(ds_dir)
glimpse(ds)## FileSystemDataset with 3 Parquet files
## 15 rows x 3 columns
## $ id <int32> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
## $ value <double> -1.400043517, 0.255317055, -2.437263611, -0.005571287, 0.62155~
## $ subset <string> "a", "a", "a", "a", "a", "b", "b", "b", "b", "b", "c", "c", "c~
## Call `print()` for full schema details如您所見,ds Dataset 物件彙總了三個單獨的資料檔案。事實上,在這種特殊情況下,Dataset 非常小,以至於所有三個檔案中的值都出現在 glimpse() 的輸出中。
應該注意的是,在日常資料分析工作中,您不需要以這種方式手動寫入資料檔案。上面的範例完全是為了說明目的。可以使用以下命令建立完全相同的資料集
ds |>
group_by(subset) |>
write_dataset("mini-dataset")事實上,即使 ds 恰好引用了比記憶體大的資料來源,此命令仍然應該有效,因為 Dataset 功能的編寫目的是確保在這樣的管道中,資料以分段方式載入,以避免耗盡記憶體。
Dataset 物件
在前一節中,我們檢查了 Dataset 的磁碟結構。現在我們轉向 Dataset 物件本身的記憶體結構(即,前一個範例中的 ds)。建立 Dataset 物件時,arrow 會搜尋資料集資料夾以尋找適當的檔案,但不會載入這些檔案的內容。這些檔案的路徑儲存在活動綁定 ds$files 中
ds$files## [1] "/build/r/vignettes/mini-dataset/subset=a/part-0.parquet"
## [2] "/build/r/vignettes/mini-dataset/subset=b/part-0.parquet"
## [3] "/build/r/vignettes/mini-dataset/subset=c/part-0.parquet"呼叫 open_dataset() 時發生的另一件事是,會為 Dataset 建構一個明確的 Schema 並將其儲存為 ds$schema
ds$schema## Schema
## id: int32
## value: double
## subset: string
##
## See $metadata for additional Schema metadata預設情況下,此 Schema 是透過僅檢查第一個檔案來推斷的,儘管可以在檢查所有檔案後建構統一的 schema。若要執行此操作,請在呼叫 open_dataset() 時設定 unify_schemas = TRUE。也可以使用 open_dataset() 的 schema 參數來明確指定 Schema(有關詳細資訊,請參閱 schema() 函數)。
讀取資料的動作由 Scanner 物件執行。當使用 dplyr 介面分析 Dataset 時,您永遠不需要手動建構 Scanner,但為了說明目的,我們將在此處執行此操作
scan <- Scanner$create(dataset = ds)呼叫 ToTable() 方法將具體化 Dataset(磁碟上)為 Table(記憶體中)
scan$ToTable()## Table
## 15 rows x 3 columns
## $id <int32>
## $value <double>
## $subset <string>
##
## See $metadata for additional Schema metadata預設情況下,此掃描程序是多線程的,但如果需要,可以在呼叫 Scanner$create() 時設定 use_threads = FALSE 來停用線程。
查詢 Dataset
當針對 Dataset 執行查詢時,會啟動新的掃描,並將結果拉回 R 中。例如,考慮以下 dplyr 表達式
ds |>
filter(value > 0) |>
mutate(new_value = round(100 * value)) |>
select(id, subset, new_value) |>
collect()## # A tibble: 6 x 3
## id subset new_value
## <int> <chr> <dbl>
## 1 2 a 26
## 2 5 a 62
## 3 6 b 115
## 4 12 c 63
## 5 13 c 207
## 6 15 c 51我們可以透過使用低階 Dataset 介面,透過指定 filter 和 projection 參數到 Scanner$create() 來建立新的掃描來複製此操作。若要使用這些參數,您需要稍微瞭解 Arrow Expressions,為此,您可能會發現閱讀 help("Expression", package = "arrow") 中的幫助文件很有幫助。
下面定義的掃描器模擬了上面顯示的 dplyr 管道,
scan <- Scanner$create(
dataset = ds,
filter = Expression$field_ref("value") > 0,
projection = list(
id = Expression$field_ref("id"),
subset = Expression$field_ref("subset"),
new_value = Expression$create("round", 100 * Expression$field_ref("value"))
)
)如果我們呼叫 as.data.frame(scan$ToTable()),它將產生與 dplyr 版本相同的結果,儘管列可能不會以相同的順序出現。
為了更好地瞭解查詢執行時發生的情況,我們將在此處呼叫 scan$ScanBatches()。與 ToTable() 方法非常相似,ScanBatches() 方法針對每個檔案單獨執行查詢,但它會傳回 Record Batches 的列表,每個檔案一個。此外,我們將單獨將這些 Record Batches 轉換為資料框
lapply(scan$ScanBatches(), as.data.frame)## [[1]]
## id subset new_value
## 1 2 a 26
## 2 5 a 62
##
## [[2]]
## id subset new_value
## 1 6 b 115
##
## [[3]]
## id subset new_value
## 1 12 c 63
## 2 13 c 207
## 3 15 c 51如果我們回到之前建立的 dplyr 查詢,並使用 compute() 傳回 Table 而不是使用 collect() 傳回資料框,我們可以看到此過程正在運作的證據。Table 物件是透過串連查詢針對三個資料檔案執行時產生的三個 Record Batches 而建立的,因此,定義 Table 列的 Chunked Array 反映了資料檔案中存在的分割結構
tbl <- ds |>
filter(value > 0) |>
mutate(new_value = round(100 * value)) |>
select(id, subset, new_value) |>
compute()
tbl$subset## ChunkedArray
## <string>
## [
## [
## "a",
## "a"
## ],
## [
## "b"
## ],
## [
## "c",
## "c",
## "c"
## ]
## ]其他注意事項
先前討論中忽略的一個區別是
FileSystemDataset和InMemoryDataset物件之間的區別。在通常情況下,構成 Dataset 的資料儲存在磁碟上的檔案中。畢竟,這是 Datasets 優於 Tables 的主要優勢。但是,在某些情況下,從已儲存在記憶體中的資料建立 Dataset 可能很有用。在這種情況下,建立的物件將具有InMemoryDataset類型。先前的討論假設儲存在 Dataset 中的所有檔案都具有相同的 Schema。在通常情況下,這將是真的,因為每個檔案在概念上都是單個矩形表格的子集。但這並不是嚴格要求的。
有關這些主題的更多資訊,請參閱 help("Dataset", package = "arrow")。