本文描述 Arrow 資料物件的內部結構。arrow R 套件的使用者通常不需要理解 Arrow 資料物件的內部結構。我們在此處包含它是為了幫助那些希望理解 Arrow 規格 的 R 使用者和 Arrow 開發人員。本文深入探討了 資料物件文章 中描述的一些主題,主要針對開發人員。對於使用 arrow 套件來說,這不是必要的知識。
我們先從描述兩個關鍵概念開始
- 陣列中的值儲存在一個或多個緩衝區中。緩衝區是一個具有給定長度的循序虛擬位址空間(即,記憶體區塊)。給定一個指定緩衝區起始記憶體位址的指標,您可以使用「偏移」值存取緩衝區中的任何位元組,該值指定相對於緩衝區起點的位置。
- 陣列的物理佈局是用於描述陣列中的資料如何在記憶體中佈局的術語,而無需考慮如何解釋該資訊。舉例來說:32 位元帶號整數和 32 位元浮點數具有相同的佈局:它們都是 32 位元,在記憶體中表示為 4 個連續的位元組。含義不同,但佈局相同。
我們可以利用一個簡單的整數值陣列來解開這些概念
integer_array <- Array$create(c(1L, NA, 2L, 4L, 8L))
integer_array## Array
## <int32>
## [
## 1,
## null,
## 2,
## 4,
## 8
## ]我們可以檢查 integer_array$type 屬性,以查看陣列中的值是否儲存為帶號 32 位元整數。當由 Arrow C++ 函式庫佈局在記憶體中時,整數陣列由兩個 metadata 和兩個儲存資料的緩衝區組成。metadata 指定陣列的長度和空值數量的計數,兩者都儲存為 64 位元整數。這些 metadata 可以使用 R 中的 integer_array$length() 和 integer_array$null_count 分別查看。與陣列關聯的緩衝區數量取決於儲存的確切資料類型。對於整數陣列,有兩個:「有效性點陣圖緩衝區」和「資料值緩衝區」。示意性地,我們可以將陣列描繪如下
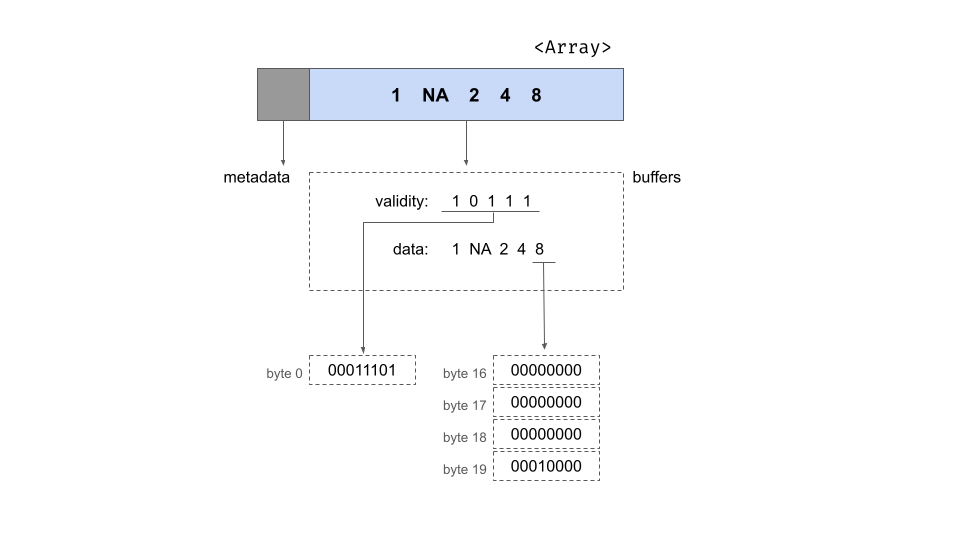
此圖像顯示了陣列為一個矩形,細分為兩個部分,一個用於 metadata,另一個用於緩衝區。在矩形下方,我們為您解開了緩衝區的內容,在虛線包圍的區域中顯示了兩個緩衝區的內容。在圖的最底部,您可以看到特定位元組的內容。
有效性點陣圖緩衝區
有效性點陣圖是二元值,只要陣列中的相應槽包含有效、非空值,就包含 1。在抽象層次上,我們可以假設它包含以下五個位元
10111然而,由於三個原因,這是一個輕微的過度簡化。首先,由於記憶體是以位元組大小的單位分配的,因此末尾有三個尾隨位元(假定為零),給我們點陣圖 10111000。其次,雖然我們是從左到右寫的,但這種書寫格式通常被認為代表 大端格式,其中最高有效位元先寫入(即,寫入最低值的記憶體位址)。Arrow 採用小端約定,當以英文書寫時,它更自然地對應於從右到左的順序。為了反映這一點,我們以從右到左的順序寫入位元:00011101。最後,Arrow 鼓勵 自然對齊的資料結構,其中分配的記憶體位址是資料區塊大小的倍數。Arrow 使用64 位元組對齊,因此每個資料結構的大小都必須是 64 位元組的倍數。此設計功能的存在是為了有效利用現代硬體,如 Arrow 規格 中討論的那樣。這就是記憶體中緩衝區的樣子
| 位元組 0(有效性點陣圖) | 位元組 1-63 |
|---|---|
00011101 |
0 (填充) |
資料緩衝區
資料緩衝區與有效性點陣圖一樣,填充到 64 位元組的長度,以保持自然對齊。這是顯示物理佈局的圖表
| 位元組 0-3 | 位元組 4-7 | 位元組 8-11 | 位元組 12-15 | 位元組 16-19 | 位元組 20-63 |
|---|---|---|---|---|---|
1 |
未指定 | 2 |
4 |
8 |
未指定 |
每個整數佔用 4 個位元組,根據 32 位元帶號整數的要求。請注意,與遺失值關聯的位元組保持未指定:已為該值分配空間,但這些位元組未被填滿。
偏移緩衝區
某些類型的 Arrow 陣列包含第三個緩衝區,稱為偏移緩衝區。這在字串陣列的上下文中最常遇到,例如這個
string_array <- Array$create(c("hello", "amazing", "and", "cruel", "world"))
string_array## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]使用與之前相同的示意符號,這是物件的結構。它具有與之前相同的 metadata,但如下所示,現在有三個緩衝區
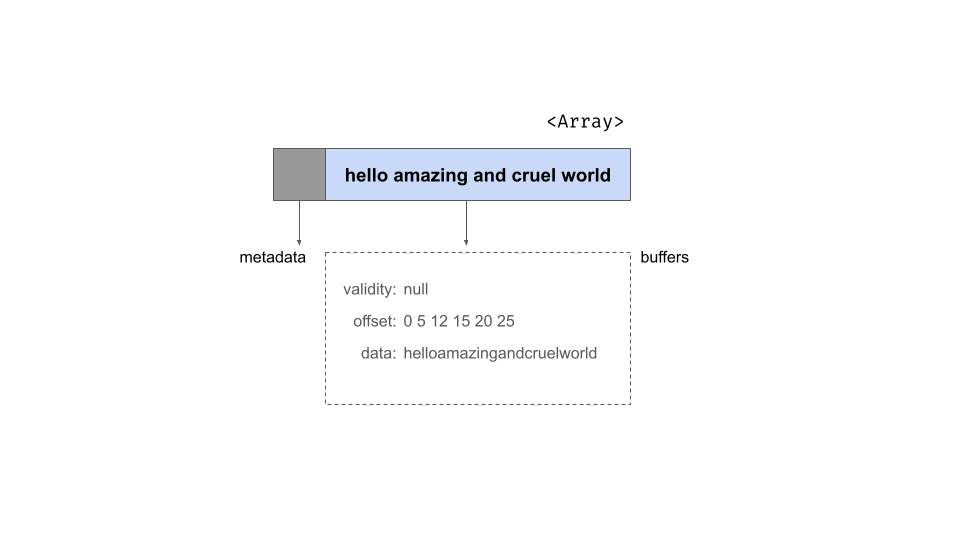
為了理解偏移緩衝區的作用,它有助於注意字串陣列的資料緩衝區格式:它將所有字串端對端地連接在記憶體的一個連續部分中。對於 string_array 物件,資料緩衝區的內容看起來像一個長 utf8 編碼字串
helloamazingandcruelworld由於個別字串的長度可能不同,因此偏移緩衝區的作用是指定槽之間邊界的位置。我們陣列中的第二個槽是字串 "amazing"。如果資料陣列中的位置索引如下
| h | e | l | l | o | a | m | a | z | i | n | g | a | n | d | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | … |
那麼我們可以看到感興趣的字串從位置 5 開始,到位置 11 結束。偏移緩衝區由整數組成,這些整數儲存這些斷點位置。對於 string_array,它可能看起來像這樣
0 5 12 15 20 25utf8() 資料類型和 large_utf8() 資料類型之間的區別在於,utf8() 資料類型將這些儲存為 32 位元整數,而 large_utf8() 類型將它們儲存為 64 位元整數。
區塊陣列
陣列是不可變的物件:一旦陣列被初始化,它儲存的值就無法更改。這確保多個實體可以透過指標安全地引用陣列,而不會冒值會更改的風險。使用不可變的陣列使 Arrow 能夠避免不必要的資料物件副本。
不可變陣列存在限制,最明顯的是當新的資料批次到達時。由於陣列是不可變的,因此您無法將新資訊新增到現有陣列。如果您不想干擾或複製現有陣列,唯一可以做的是建立一個包含新資料的新陣列。這樣做可以保留陣列的不可變性,並且不會導致任何不必要的複製,但現在我們有一個新問題:資料分散在兩個陣列中。每個陣列僅包含資料的一個「區塊」。理想情況下,我們需要一個抽象層,使我們能夠將這兩個陣列視為單個「類陣列」物件。
這就是區塊陣列解決的問題。區塊陣列是陣列列表的包裝器,它允許您索引它們的內容,就好像它們是單個陣列一樣。從物理上講,資料仍然儲存在不同的位置——每個陣列都是一個區塊,並且這些區塊不必在記憶體中彼此相鄰——但區塊陣列為我們提供了一個抽象層,使我們能夠假裝它們都是一個東西。
為了說明,讓我們使用 chunked_array() 函數
chunked_string_array <- chunked_array(
c("hello", "amazing", "and", "cruel", "world"),
c("I", "love", "you")
)chunked_array() 函數只是 ChunkedArray$create() 提供的功能的包裝器。讓我們看一下物件
chunked_string_array## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ],
## [
## "I",
## "love",
## "you"
## ]
## ]此輸出中的雙括號旨在突出顯示區塊陣列的「類列表」性質。有三個單獨的陣列,包裹在一個容器物件中,該容器物件實際上是一個陣列列表,但允許該列表的行為就像常規的一維資料結構一樣。示意性地,它看起來像這樣
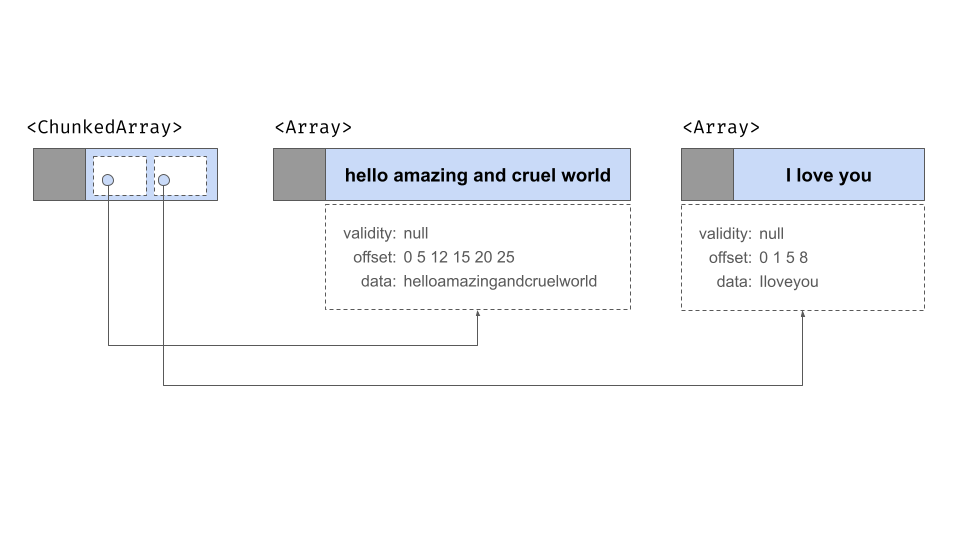
如圖所示,這裡確實有三個陣列,每個陣列都有自己的有效性點陣圖、偏移緩衝區和資料緩衝區。
記錄批次
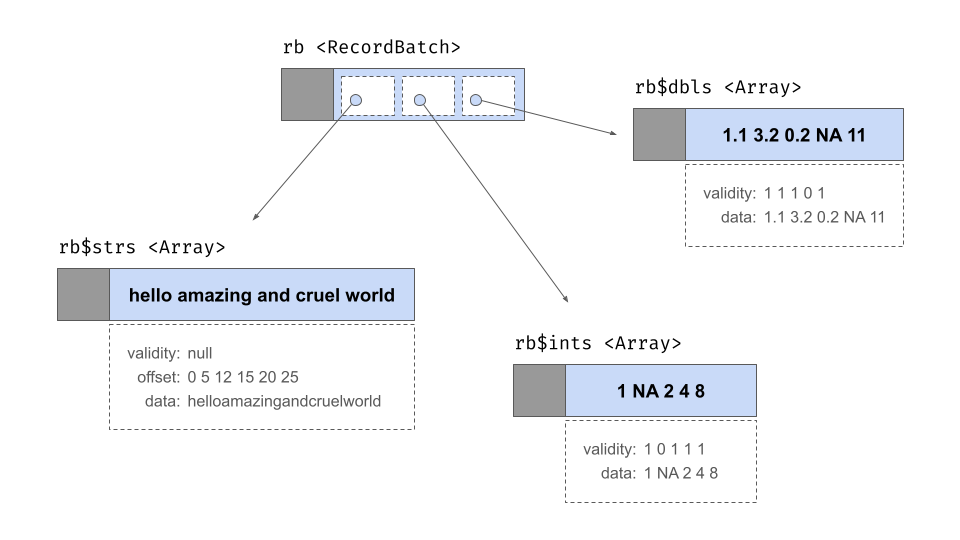
記錄批次是類似表格的資料結構,由一系列陣列組成。陣列可以是不同的類型,但它們的長度必須相同。每個陣列都稱為記錄批次的「欄位」或「欄」。每個欄位都必須有一個(UTF8 編碼的)名稱,並且這些名稱構成記錄批次的 metadata 的一部分。當儲存在記憶體中時,記錄批次不包含每個欄位中儲存的值的物理儲存:相反,它包含指向相關陣列物件的指標。但是,它確實包含自己的有效性點陣圖。
這是一個包含 5 列和 3 行的記錄批次
rb <- record_batch(
strs = c("hello", "amazing", "and", "cruel", "world"),
ints = c(1L, NA, 2L, 4L, 8L),
dbls = c(1.1, 3.2, 0.2, NA, 11)
)
rb## RecordBatch
## 5 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>在抽象層次上,rb 物件的行為類似於具有行和列的二維結構,但在記憶體中的表示方式方面,它本質上是一個陣列列表,如下所示
表格
為了處理矩形資料集可以隨著時間推移而增長(隨著更多資料被新增)的情況,我們需要一個表格資料結構,該結構與記錄批次類似,但有一個例外:我們現在不想將每列儲存為陣列,而是希望將其儲存為區塊陣列。這就是 arrow 中的 Table 類別的作用。
為了說明,假設我們有第二組資料以記錄批次的形式到達
new_rb <- record_batch(
strs = c("I", "love", "you"),
ints = c(5L, 0L, 0L),
dbls = c(7.1, -0.1, 2)
)
df <- concat_tables(arrow_table(rb), arrow_table(new_rb))
df## Table
## 8 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>這是此表格的底層結構
