在 Apache Arrow DataFusion 28.0.0 中快速聚合數百萬個群組
已發布 2023 年 8 月 5 日
作者 alamb, Dandandan, tustvold
在 Apache Arrow DataFusion 中快速聚合數百萬個群組
Andrew Lamb, Daniël Heres, Raphael Taylor-Davies,
注意:本文最初發布於 InfluxData 部落格
太長不看 (TLDR)
分組聚合是任何分析工具的核心部分,可為大量資料建立易於理解的摘要。Apache Arrow DataFusion 的平行聚合功能在新發布的 版本 28.0.0 中,對於具有大量(10,000 個或更多)群組的查詢,速度提高了 2-3 倍。
改進聚合效能對於 DataFusion 的所有使用者都很重要。例如,時間序列資料平台 InfluxDB 和 全堆疊可觀測性 平台 Coralogix 都會聚合大量原始資料,以監控並為我們的客戶建立洞察。改進 DataFusion 的效能使我們能夠透過更少的資源更快地產生洞察,從而提供更好的使用者體驗。由於 DataFusion 是開源的,並在寬鬆的 Apache 2.0 授權下發布,因此整個 DataFusion 社群也受益。
透過新的最佳化,DataFusion 的分組速度現在已接近 DuckDB,DuckDB 是一個定期報告 出色 分組 基準效能數字的系統。圖 1 包含 ClickBench 在單個 Parquet 檔案上的代表性範例,完整結果位於本文末尾。
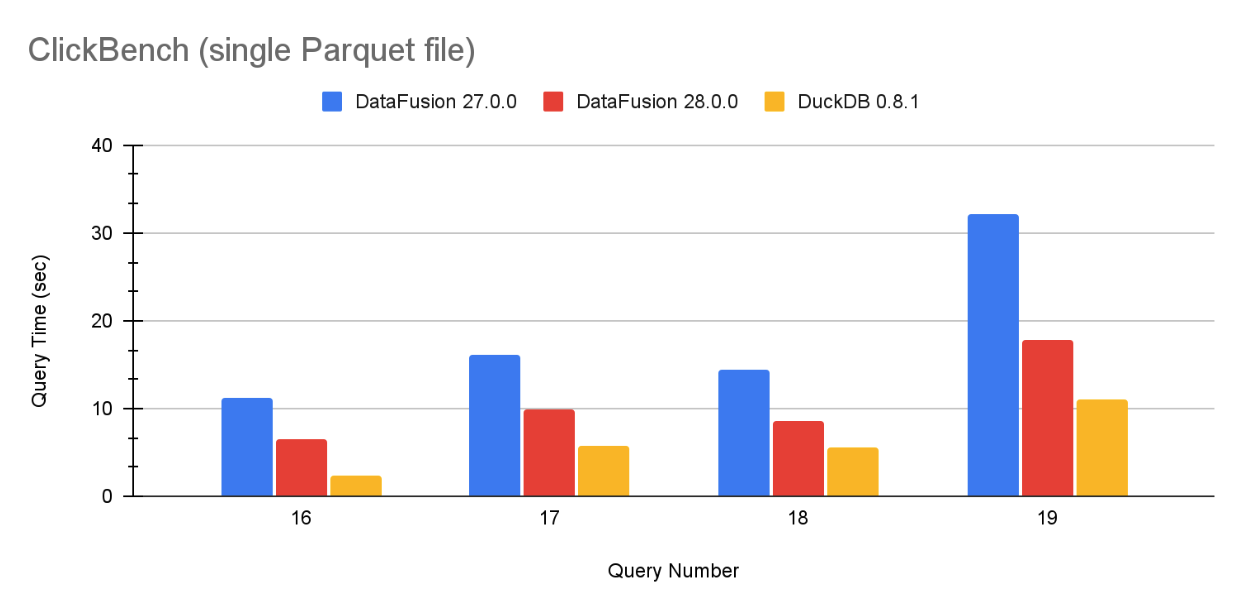
圖 1:DataFusion 27.0.0、DataFusion 28.0.0 和 DuckDB 0.8.1 在單個 Parquet 檔案上針對查詢 16、17、18 和 19 的 ClickBench 查詢效能。
高基數分組簡介
聚合是一個用於計算多行摘要統計資訊的術語,這些行在一個或多個欄位中具有相同的值。我們將具有相同值的行稱為群組,「高基數」表示資料集中有大量不同的群組。在撰寫本文時,分析引擎中「大量」群組約為 10,000 個。
例如,ClickBench hits 資料集包含 1 億次跨多個網站的匿名使用者點擊。ClickBench 查詢 17 是
SELECT "UserID", "SearchPhrase", COUNT(*)
FROM hits
GROUP BY "UserID", "SearchPhrase"
ORDER BY COUNT(*)
DESC LIMIT 10;
用英文來說,此查詢查找「所有點擊次數中前十名(使用者、搜尋詞組)組合」,並產生以下結果(前十名使用者沒有搜尋詞組)
+---------------------+--------------+-----------------+
| UserID | SearchPhrase | COUNT(UInt8(1)) |
+---------------------+--------------+-----------------+
| 1313338681122956954 | | 29097 |
| 1907779576417363396 | | 25333 |
| 2305303682471783379 | | 10597 |
| 7982623143712728547 | | 6669 |
| 7280399273658728997 | | 6408 |
| 1090981537032625727 | | 6196 |
| 5730251990344211405 | | 6019 |
| 6018350421959114808 | | 5990 |
| 835157184735512989 | | 5209 |
| 770542365400669095 | | 4906 |
+---------------------+--------------+-----------------+
ClickBench 資料集包含
- 99,997,497 總行數1
- 17,630,976 個不同的使用者(不同的 UserID)2
- 6,019,103 個不同的搜尋詞組3
- 24,070,560 個不同的 (UserID, SearchPhrase) 組合4。因此,為了回答查詢,DataFusion 必須將 1 億個不同的輸入行中的每一個對應到 2400 萬個不同的群組 之一,並記錄每個群組中有多少行。
解決方案
與資料庫和其他分析系統中的大多數概念一樣,此演算法的基本概念很簡單,並在入門電腦科學課程中教授。您可以使用如下程式計算查詢5
import pandas as pd
from collections import defaultdict
from operator import itemgetter
# read file
hits = pd.read_parquet('hits.parquet', engine='pyarrow')
# build groups
counts = defaultdict(int)
for index, row in hits.iterrows():
group = (row['UserID'], row['SearchPhrase']);
# update the dict entry for the corresponding key
counts[group] += 1
# Print the top 10 values
print (dict(sorted(counts.items(), key=itemgetter(1), reverse=True)[:10]))
這種方法雖然簡單,但速度慢且記憶體效率非常低。它需要超過 40 秒才能計算不到 1% 資料集的結果6。DataFusion 28.0.0 和 DuckDB 0.8.1 都可以在 10 秒內計算出整個資料集的結果。
為了快速有效地回答此查詢,您必須編寫程式碼,使其能夠
- 透過平行化計算保持所有核心忙於聚合
- 快速更新聚合值,使用向量化迴圈,編譯器可以輕鬆地將其轉換為現代 CPU 中可用的高效能 SIMD 指令。
本文的其餘部分將說明分組在 DataFusion 中的運作方式以及我們在 28.0.0 中所做的改進。
兩階段平行分割分組
DataFusion 27.0. 和 28.0.0 都使用最先進的兩階段平行雜湊分割分組,類似於其他高效能向量化引擎,如 DuckDB 的平行分組聚合。用圖示表示如下
▲ ▲
│ │
│ │
│ │
┌───────────────────────┐ ┌───────────────────┐
│ GroupBy │ │ GroupBy │ Step 4
│ (Final) │ │ (Final) │
└───────────────────────┘ └───────────────────┘
▲ ▲
│ │
└────────────┬───────────┘
│
│
┌─────────────────────────┐
│ Repartition │ Step 3
│ HASH(x) │
└─────────────────────────┘
▲
│
┌────────────┴──────────┐
│ │
│ │
┌────────────────────┐ ┌─────────────────────┐
│ GroupyBy │ │ GroupBy │ Step 2
│ (Partial) │ │ (Partial) │
└────────────────────┘ └─────────────────────┘
▲ ▲
┌──┘ └─┐
│ │
.─────────. .─────────.
,─' '─. ,─' '─.
; Input : ; Input : Step 1
: Stream 1 ; : Stream 2 ;
╲ ╱ ╲ ╱
'─. ,─' '─. ,─'
`───────' `───────'
圖 2:兩階段重新分割分組:資料從底部(來源)流向頂部(結果),分為兩個階段。首先(步驟 1 和 2),每個核心將資料讀取到核心特定的雜湊表,計算中間聚合,而無需任何跨核心協調。然後(步驟 3 和 4),DataFusion 按群組值將資料(「重新分割」)劃分為不同的子集,每個子集都發送到特定的核心,該核心計算最終聚合。
這兩個階段對於在多核心系統中保持核心忙碌至關重要。這兩個階段都使用相同的雜湊表方法(在下一節中說明),但在群組的分發方式和累加器發出的部分結果方面有所不同。第一階段在產生資料後立即聚合資料。但是,如圖 2 所示,群組可以位於任何輸入中的任何位置,因此同一個群組通常在許多不同的核心上找到。第二階段使用雜湊函數將資料均勻地重新分發到各個核心,因此每個群組值都由一個核心處理,該核心發出該群組的最終結果。
┌─────┐ ┌─────┐
│ 1 │ │ 3 │
│ 2 │ │ 4 │ 2. After Repartitioning: each
└─────┘ └─────┘ group key appears in exactly
┌─────┐ ┌─────┐ one partition
│ 1 │ │ 3 │
│ 2 │ │ 4 │
└─────┘ └─────┘
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
┌─────┐ ┌─────┐
│ 2 │ │ 2 │
│ 1 │ │ 2 │
│ 3 │ │ 3 │
│ 4 │ │ 1 │
└─────┘ └─────┘ 1. Input Stream: groups
... ... values are spread
┌─────┐ ┌─────┐ arbitrarily over each input
│ 1 │ │ 4 │
│ 4 │ │ 3 │
│ 1 │ │ 1 │
│ 4 │ │ 3 │
│ 3 │ │ 2 │
│ 2 │ │ 2 │
│ 2 │ └─────┘
└─────┘
Core A Core B
圖 3:聚合階段期間跨 2 個核心的群組值分佈。在第一階段,每個群組值 1、2、3、4 都存在於每個核心處理的輸入流中。在第二階段,重新分割後,群組值 1 和 2 由核心 A 處理,值 3 和 4 僅由核心 B 處理。
DataFusion 實作中還有一些未在上面提及的細微之處,因為空間有限,例如
- 何時從第一階段的雜湊表發出資料的策略(例如,因為資料是部分排序的)
- 處理每個聚合的特定篩選器(由於
FILTERSQL 子句) - 中間值的資料類型(對於某些聚合(如
AVG),可能與最終輸出不同)。 - 當記憶體使用量超過其預算時採取的行動。
雜湊分組
DataFusion 查詢可以為每個群組計算許多不同的聚合函數,包括 內建 和/或使用者定義的 AggregateUDFs。每個聚合函數的狀態(稱為累加器)都使用雜湊表追蹤(DataFusion 使用出色的 HashBrown RawTable API),該雜湊表邏輯上儲存了識別特定群組值的「索引」。
27.0.0 中的雜湊分組
如圖 3 所示,DataFusion 27.0.0 將資料儲存在 GroupState 結構中,不出所料,該結構追蹤每個群組的狀態。每個群組的狀態包括
- 群組欄位的實際值,採用 Arrow Row 格式。
- 每個群組的正在進行的累加(例如,
COUNT聚合的執行計數),採用兩種可能的格式之一(Accumulator或RowAccumulator)。 - 用於追蹤每個批次中哪些行符合每個聚合的暫存空間。
┌──────────────────────────────────────┐
│ │
│ ... │
│ ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ │
│ ┃ ┃ │
┌─────────┐ │ ┃ ┌──────────────────────────────┐ ┃ │
│ │ │ ┃ │group values: OwnedRow │ ┃ │
│ ┌─────┐ │ │ ┃ └──────────────────────────────┘ ┃ │
│ │ 5 │ │ │ ┃ ┌──────────────────────────────┐ ┃ │
│ ├─────┤ │ │ ┃ │Row accumulator: │ ┃ │
│ │ 9 │─┼────┐ │ ┃ │Vec<u8> │ ┃ │
│ ├─────┤ │ │ │ ┃ └──────────────────────────────┘ ┃ │
│ │ ... │ │ │ │ ┃ ┌──────────────────────┐ ┃ │
│ ├─────┤ │ │ │ ┃ │┌──────────────┐ │ ┃ │
│ │ 1 │ │ │ │ ┃ ││Accumulator 1 │ │ ┃ │
│ ├─────┤ │ │ │ ┃ │└──────────────┘ │ ┃ │
│ │ ... │ │ │ │ ┃ │┌──────────────┐ │ ┃ │
│ └─────┘ │ │ │ ┃ ││Accumulator 2 │ │ ┃ │
│ │ │ │ ┃ │└──────────────┘ │ ┃ │
└─────────┘ │ │ ┃ │ Box<dyn Accumulator> │ ┃ │
Hash Table │ │ ┃ └──────────────────────┘ ┃ │
│ │ ┃ ┌─────────────────────────┐ ┃ │
│ │ ┃ │scratch indices: Vec<u32>│ ┃ │
│ │ ┃ └─────────────────────────┘ ┃ │
│ │ ┃ GroupState ┃ │
└─────▶ │ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛ │
│ │
Hash table tracks an │ ... │
index into group_states │ │
└──────────────────────────────────────┘
group_states: Vec<GroupState>
There is one GroupState PER GROUP
圖 4:DataFusion 27.0.0 中的雜湊群組運算子結構。雜湊表將每個群組對應到一個 GroupState,其中包含所有每個群組的狀態。
為了計算聚合,DataFusion 對於每個輸入批次執行以下步驟
- 使用 高效向量化程式碼計算雜湊,專門針對每種資料類型。
- 使用雜湊表確定每個輸入行的群組索引(為新看到的群組建立新條目)。
- 更新具有輸入行的每個群組的累加器, 如果有足夠數量的行,則將這些行組裝成連續範圍以進行向量化累加器。
DataFusion 也將雜湊值儲存在表中,以避免在調整雜湊表大小時可能產生高成本的雜湊重新計算。
這種方案對於相對少量不同的群組非常有效:所有累加器都使用大量連續的行批次有效地更新。
但是,由於以下原因,此方案不適用於高基數分組
- 每個群組的多個配置,用於群組值行格式,以及用於
RowAccumulator和每個Accumulator。Accumulator也可能在其內部有額外的配置。 - 非向量化更新: 由於每個輸入批次中不同群組的數量很大(因此每個群組的值數量很小),累加器更新通常會退回到較慢的非向量化形式。
28.0.0 中的雜湊分組
對於 28.0.0,我們遵循傳統的系統最佳化原則重寫了核心群組依據實作:更少的配置、類型特化和積極的向量化。
DataFusion 28.0.0 使用相同的 RawTable 並且仍然儲存群組索引。如圖 4 所示,主要差異在於
- 群組值儲存為
- 內聯在
RawTable中(對於原始類型的單個欄位),其中轉換為 Row 格式的成本高於其優勢 - 在單獨的 Rows 結構中,所有群組值都使用單個連續配置,而不是每個群組一個配置。累加器在內部管理所有群組的狀態,因此更新中間值的程式碼是一個緊密的類型特化迴圈。新的
GroupsAccumulator介面產生了高效的類型累加器更新迴圈。
- 內聯在
┌───────────────────────────────────┐ ┌───────────────────────┐
│ ┌ ─ ─ ─ ─ ─ ┐ ┌─────────────────┐│ │ ┏━━━━━━━━━━━━━━━━━━━┓ │
│ │ ││ │ ┃ ┌──────────────┐ ┃ │
│ │ │ │ ┌ ─ ─ ┐┌─────┐ ││ │ ┃ │┌───────────┐ │ ┃ │
│ │ X │ 5 │ ││ │ ┃ ││ value1 │ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ │└───────────┘ │ ┃ │
│ │ Q │ 9 │──┼┼──┐ │ ┃ │ ... │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ └──┼─╋─▶│ │ ┃ │
│ │ ... │ ... │ ││ │ ┃ │┌───────────┐ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ ││ valueN │ │ ┃ │
│ │ H │ 1 │ ││ │ ┃ │└───────────┘ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ │values: Vec<T>│ ┃ │
│ Rows │ ... │ ... │ ││ │ ┃ └──────────────┘ ┃ │
│ │ │ │ └ ─ ─ ┘└─────┘ ││ │ ┃ ┃ │
│ ─ ─ ─ ─ ─ ─ │ ││ │ ┃ GroupsAccumulator ┃ │
│ └─────────────────┘│ │ ┗━━━━━━━━━━━━━━━━━━━┛ │
│ Hash Table │ │ │
│ │ │ ... │
└───────────────────────────────────┘ └───────────────────────┘
GroupState Accumulators
Hash table value stores group_indexes One GroupsAccumulator
and group values. per aggregate. Each
stores the state for
Group values are stored either inline *ALL* groups, typically
in the hash table or in a single using a native Vec<T>
allocation using the arrow Row format
圖 5:DataFusion 28.0.0 中的雜湊群組運算子結構。群組值直接儲存在雜湊表中,或使用 arrow Row 格式以單個配置儲存。雜湊表包含群組索引。單個 GroupsAccumulator 儲存所有群組的每個聚合狀態。
由於以下原因,這種新結構顯著提高了高基數群組的效能
- 減少配置:不再有每個群組的個別配置。
- 連續原生累加器狀態:類型特化的累加器使用某些原生類型的 Rust Vec<T> 在單個連續配置中儲存所有群組的值。
- 向量化狀態更新:內部聚合更新迴圈(類型特化且以原生
Vec表示)由 Rust 編譯器(感謝 LLVM!)良好地向量化。
註記
一些向量化分組實作將累加器狀態按行方式直接儲存在雜湊表中,這通常有效地利用了現代 CPU 快取。以欄位方式管理累加器狀態可能會犧牲一些快取局部性,但是,它可以確保雜湊表的大小保持較小,即使在有大量群組和聚合時也是如此,從而使編譯器更容易向量化累加器更新。
根據重新計算雜湊值的成本,DataFusion 28.0.0 可能會或可能不會將雜湊值儲存在表中。這最佳化了計算雜湊值的成本(例如,對於字串來說成本很高)與將其儲存在雜湊表中的成本之間的權衡。
將狀態更新推送到 GroupsAccumulators 中產生的一個微妙之處是,每個累加器都必須處理類似的變化,包括有/無篩選以及輸入中包含/不包含 Null 值。DataFusion 28.0.0 使用範本化的 NullState,它封裝了跨累加器的這些常見模式。
程式碼結構在很大程度上受到 DataFusion 是使用 Rust 實作的事實的影響,Rust 是一種專注於速度和安全性的新(ish)系統程式設計語言。Rust 強烈反對 C/C++ 雜湊分組實作中使用的許多傳統指標轉換「技巧」。DataFusion 聚合程式碼幾乎完全是 safe,僅在必要時才偏離到 unsafe。(Rust 是一個很棒的選擇,因為它使 DataFusion 快速、易於嵌入,並防止與多執行緒 C/C++ 程式碼相關的許多崩潰和安全性問題)。
ClickBench 結果
以下是針對 DataFusion 27.0.0、DataFusion 28.0.0 和 DuckDB 0.8.1 執行 ClickBench 查詢的單個 Parquet 檔案的完整結果。這些數字是在具有 8 個核心和 32 GB RAM 的 GCP e2-standard-8 machine 上使用 此處的腳本執行的。
隨著產業朝著由組件組成的資料系統發展,越來越重要的是,它們使用 Apache Arrow 和 Parquet 等開放標準而不是自訂儲存和記憶體格式來交換資料。因此,此基準測試使用代表許多 DataFusion 使用者的單個輸入 Parquet 檔案,並與目前分析避免在查詢之前將成本高昂的載入/轉換為自訂儲存格式的趨勢保持一致。
DataFusion 現在在查詢 Parquet 資料時達到接近 DuckDB 的速度。雖然我們不打算與一個實際上撰寫了 Fair Benchmarking Considered Difficult 的團隊進行基準測試競賽,但希望大家都能同意 DataFusion 28.0.0 是一項重大改進。
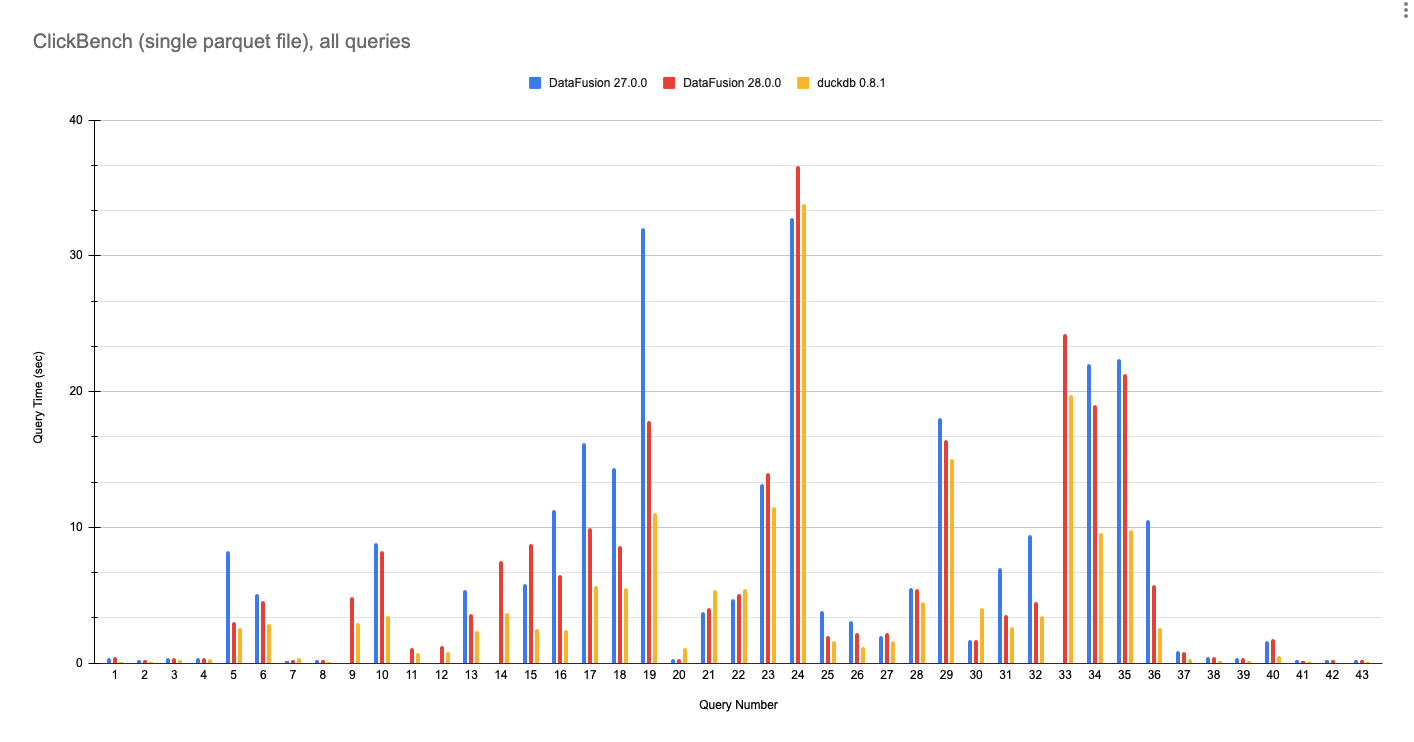
圖 6:DataFusion 27.0.0、DataFusion 28.0.0 和 DuckDB 0.8.1 在針對單個 hits.parquet 檔案的所有 43 個 ClickBench 查詢上的效能。數值越低越好。
註記
DataFusion 27.0.0 由於規劃器錯誤(Q9、Q11、Q12、14)或記憶體不足(Q33)而無法執行多個查詢。DataFusion 28.0.0 解決了這些問題。
DataFusion 在查詢 21 和 22 中比 DuckDB 更快,這可能是由於字串模式比對的最佳化實作。
結論:效能至關重要
將聚合效能提高兩倍以上,使使用 DataFusion 建立產品和專案的開發人員能夠將更多時間花在具有附加價值的特定領域功能上。我們相信使用 DataFusion 建立系統比從頭開始建立類似系統要快得多。DataFusion 提高了生產力,因為它消除了重建已充分理解但實作成本高昂的分析資料庫技術的需要。雖然我們對 DataFusion 28.0.0 的改進感到滿意,但我們絕非止步於此,並且正在追求 (更多)聚合效能。效能的未來是光明的。
致謝
DataFusion 是一個 社群努力 的成果,如果沒有社群中許多人的貢獻,這項工作是不可能完成的。特別感謝 sunchao、yjshen、yahoNanJing、mingmwang、ozankabak、mustafasrepo 以及其他所有在 此 工作 期間貢獻想法、評論和鼓勵的人。
關於 DataFusion
Apache Arrow DataFusion 是一個可擴展的查詢引擎和資料庫工具組,用 Rust 編寫,它使用 Apache Arrow 作為其記憶體格式。DataFusion 以及 Apache Calcite、Facebook 的 Velox 和類似技術是下一代「解構資料庫」架構的一部分,其中新系統建立在快速、模組化組件的基礎上,而不是作為單個緊密集成的系統。
註記
-
SELECT COUNT(*) FROM 'hits.parquet';↩ -
SELECT COUNT(DISTINCT "UserID") as num_users FROM 'hits.parquet';↩ -
SELECT COUNT(DISTINCT "SearchPhrase") as num_phrases FROM 'hits.parquet';↩ -
SELECT COUNT(*) FROM (SELECT DISTINCT "UserID", "SearchPhrase" FROM 'hits.parquet')↩ -
hits_0.parquet,來自分割的 ClickBench 資料集的一個檔案,它有
100,000行,大小為 117 MB。整個資料集在單個 14 GB Parquet 檔案中有100,000,000行。該腳本在 40 分鐘後未在整個資料集上完成,並且在峰值時使用了 212 GB RAM。 ↩