Skyhook:透過 Apache Arrow 將運算帶入儲存
已發布 2022年1月31日
作者: Jayjeet Chakraborty, Carlos Maltzahn, David Li, Tom Drabas
CPU、記憶體、儲存和網路頻寬每年都在進步,但它們的改進幅度在不同方面有所差異。處理器速度更快,但記憶體頻寬卻沒有跟上;同時,雲端運算導致儲存與應用程式透過網路連結分離。這種發散式演進意味著我們需要重新思考在何處以及何時執行運算,才能充分利用可用的資源。
例如,當在 Ceph 或 Amazon S3 等儲存系統上查詢資料集時,所有過濾資料的工作都由用戶端完成。資料必須透過網路傳輸,然後用戶端必須花費寶貴的 CPU 週期來解碼,最終卻因為篩選條件而丟棄。雖然像 Apache Parquet 這樣的格式可以實現一些最佳化,但從根本上來說,責任完全在用戶端。同時,即使儲存系統本身具有運算能力,它也僅僅被降級為提供「啞位元組」的角色。
感謝加州大學聖塔克魯茲分校開源軟體研究中心 (CROSS),Apache Arrow 7.0.0 版本包含了 Skyhook,這是一個 Arrow Datasets 擴充功能,透過利用儲存層來減少用戶端資源的使用率,從而解決了這個問題。我們將檢視圍繞 Skyhook 的發展以及 Skyhook 的運作方式。
介紹可程式化儲存
Skyhook 是可程式化儲存的一個範例:從儲存系統中公開更高等級的功能,供用戶端在其基礎上建構。這使我們能夠更好地利用現有系統中的資源(包括硬體和開發工作),減少每個用戶端常見操作的實作負擔,並使這些操作能夠隨著儲存層擴展。
從歷史上看,像 Apache Hadoop 這樣的大數據系統曾嘗試將運算和儲存共置以提高效率。最近,雲端和分散式運算為了靈活性和可擴展性而分離了運算和儲存,但犧牲了效能。可程式化儲存在這兩個目標之間取得平衡,允許某些操作在靠近資料的位置執行,同時在高層級上仍保持資料和運算的獨立性。
特別是,Skyhook 建構於 Ceph 之上,Ceph 是一個分散式儲存系統,可以擴展到 EB 級別的資料,同時保持可靠性和靈活性。Ceph 透過其 Object Class SDK 實現了可程式化儲存,允許擴充功能定義具有自訂功能的新物件類型。
Skyhook 架構
讓我們看看 Skyhook 如何應用這些想法。總體而言,這個想法很簡單:用戶端應該能夠要求 Ceph 執行基本操作,例如解碼檔案、過濾資料和選擇欄位。這樣一來,工作就可以使用現有的儲存叢集資源來完成,這意味著它既靠近資料,又可以隨著叢集大小而擴展。此外,這減少了透過網路傳輸的資料量,當然也減少了用戶端的工作負載。
在儲存系統端,Skyhook 使用 Ceph Object Class SDK 在 Parquet 或 Feather 格式的儲存資料上定義掃描操作。為了實作這些操作,Skyhook 首先在 Ceph 的物件儲存層中實作檔案系統墊片 (shim),然後在其之上使用 Arrow Datasets 程式庫現有的過濾和投影功能。
然後,Skyhook 在 Arrow Datasets 層中定義了一個自訂「檔案格式」。針對此類檔案的查詢會轉換為對 Ceph 的直接請求,使用那些新操作,繞過傳統的 POSIX 檔案系統層。在解碼、過濾和投影之後,Ceph 將 Arrow 記錄批次直接傳送給用戶端,最大限度地減少編碼/解碼的 CPU 額外開銷,這是 Arrow 實現的另一個最佳化。記錄批次使用 Arrow 的壓縮支援進一步節省頻寬。
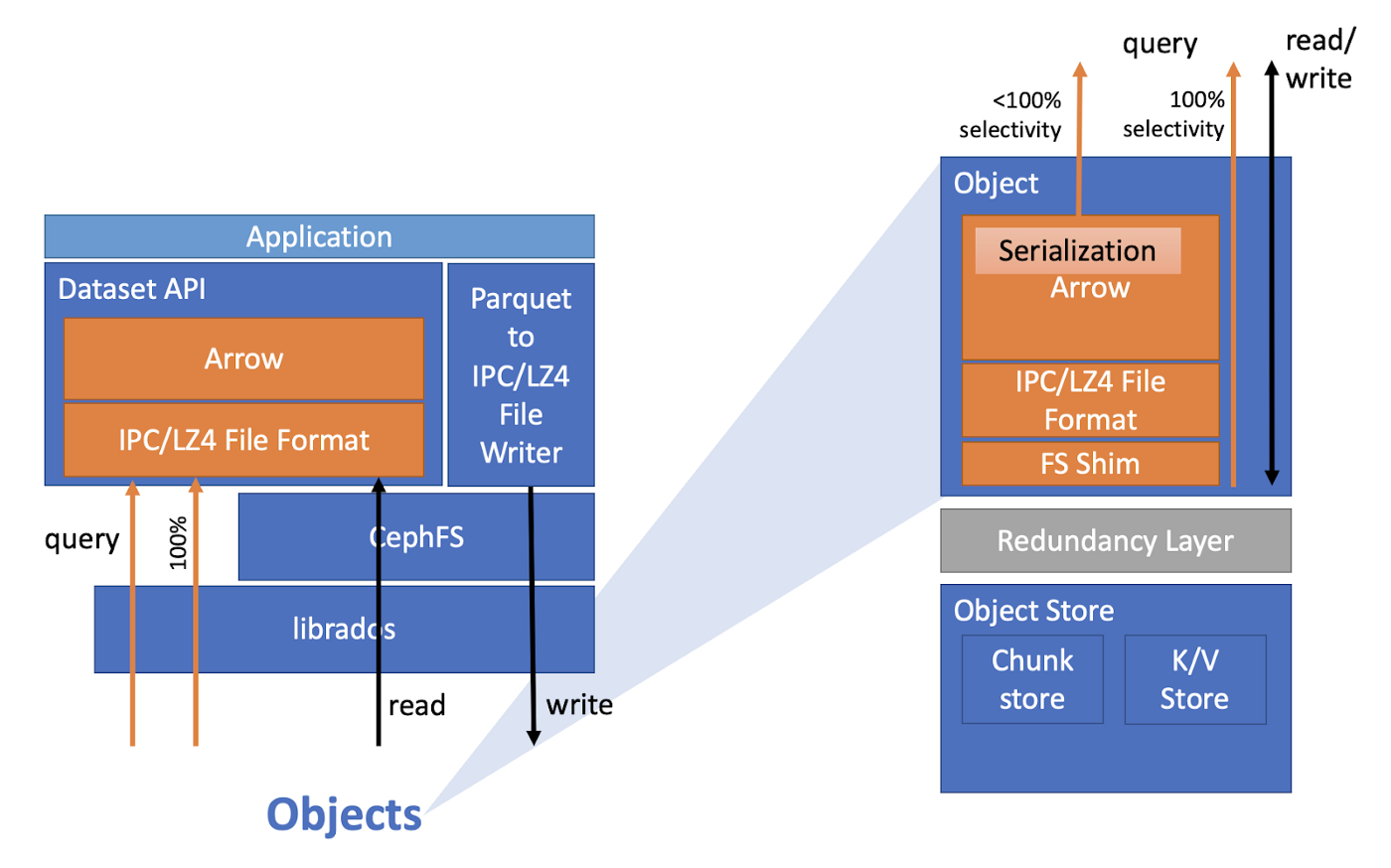
Skyhook 擴展了 Ceph 和 Arrow Datasets,將查詢下推到 Ceph,減少了用戶端的工作負載和網路流量。(圖表來源:“SkyhookDM is now a part of Apache Arrow!”。)
Skyhook 還最佳化了 Parquet 檔案的特定儲存方式。Parquet 檔案由一系列的列組 (row group) 組成,每個列組都包含檔案中的一部分列。在儲存此類檔案時,Skyhook 要麼填充要麼分割它們,以便每個列組都作為自己的 Ceph 物件儲存。透過以這種方式條帶化或分割檔案,我們可以跨 Ceph 節點以子檔案粒度並行掃描,以進一步提高效能。
應用
在基準測試中,Skyhook 具有最小的儲存端 CPU 額外開銷,並且幾乎消除了用戶端 CPU 的使用率。擴展儲存叢集會成比例地減少查詢延遲。對於像 Dask 這樣使用 Arrow Datasets API 的系統來說,這意味著僅僅透過切換到 Skyhook 檔案格式,我們就可以加速資料集掃描,減少需要傳輸的資料量,並釋放 CPU 資源用於運算。
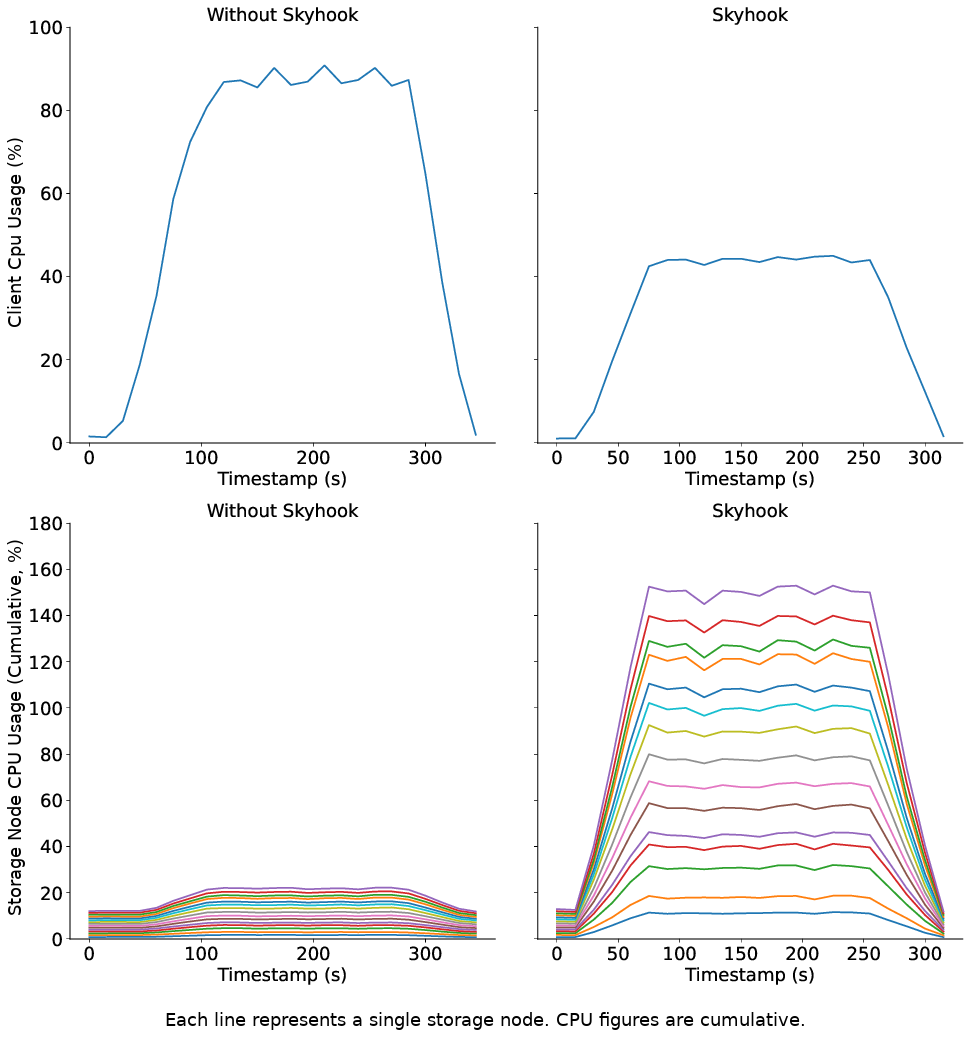
當然,Skyhook 背後的理念適用於與 Apache Arrow 相鄰和超越 Apache Arrow 的其他系統。例如,像 Apache Iceberg 和 Delta Lake 這樣的「湖倉一體 (lakehouse)」系統也建立在分散式儲存系統之上,並且可以自然地受益於 Skyhook 以卸載運算。此外,像 DuckDB 這樣的記憶體內基於 SQL 的查詢引擎與 Apache Arrow 無縫整合,可以透過卸載部分 SQL 查詢來受益於 Skyhook。
總結與致謝
Skyhook 在 Arrow 7.0.0 版本中可用,它建立在可程式化儲存系統的研究基礎之上。透過將過濾器和投影下推到儲存層,我們可以透過釋放用戶端上寶貴的 CPU 資源、減少透過網路傳送的資料量以及更好地利用像 Ceph 這樣的系統的可擴展性來加速資料集掃描。若要開始使用,只需建置啟用 Skyhook 的 Arrow、將 Skyhook 物件類別擴充功能部署到 Ceph(請參閱公告文章中的「用法」),然後使用 SkyhookFileFormat 建構 Arrow 資料集。此處顯示了一個小的程式碼範例。
// Licensed to the Apache Software Foundation (ASF) under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use this file except in compliance
// with the License. You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing,
// software distributed under the License is distributed on an
// "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
// KIND, either express or implied. See the License for the
// specific language governing permissions and limitations
// under the License.
#include <arrow/compute/api.h>
#include <arrow/dataset/api.h>
#include <arrow/filesystem/api.h>
#include <arrow/table.h>
#include <skyhook/client/file_skyhook.h>
#include <cstdlib>
#include <iostream>
#include <memory>
#include <string>
namespace cp = arrow::compute;
namespace ds = arrow::dataset;
namespace fs = arrow::fs;
// Demonstrate reading a dataset via Skyhook.
arrow::Status ScanDataset() {
// Configure SkyhookFileFormat to connect to our Ceph cluster.
std::string ceph_config_path = "/etc/ceph/ceph.conf";
std::string ceph_data_pool = "cephfs_data";
std::string ceph_user_name = "client.admin";
std::string ceph_cluster_name = "ceph";
std::string ceph_cls_name = "skyhook";
std::shared_ptr<skyhook::RadosConnCtx> rados_ctx =
std::make_shared<skyhook::RadosConnCtx>(ceph_config_path, ceph_data_pool,
ceph_user_name, ceph_cluster_name,
ceph_cls_name);
ARROW_ASSIGN_OR_RAISE(auto format,
skyhook::SkyhookFileFormat::Make(rados_ctx, "parquet"));
// Create the filesystem.
std::string root;
ARROW_ASSIGN_OR_RAISE(auto fs, fs::FileSystemFromUri("file:///mnt/cephfs/nyc", &root));
// Create our dataset.
fs::FileSelector selector;
selector.base_dir = root;
selector.recursive = true;
ds::FileSystemFactoryOptions options;
options.partitioning = std::make_shared<ds::HivePartitioning>(
arrow::schema({arrow::field("payment_type", arrow::int32()),
arrow::field("VendorID", arrow::int32())}));
ARROW_ASSIGN_OR_RAISE(auto factory,
ds::FileSystemDatasetFactory::Make(fs, std::move(selector),
std::move(format), options));
ds::InspectOptions inspect_options;
ds::FinishOptions finish_options;
ARROW_ASSIGN_OR_RAISE(auto schema, factory->Inspect(inspect_options));
ARROW_ASSIGN_OR_RAISE(auto dataset, factory->Finish(finish_options));
// Scan the dataset.
auto filter = cp::greater(cp::field_ref("payment_type"), cp::literal(2));
ARROW_ASSIGN_OR_RAISE(auto scanner_builder, dataset->NewScan());
ARROW_RETURN_NOT_OK(scanner_builder->Filter(filter));
ARROW_RETURN_NOT_OK(scanner_builder->UseThreads(true));
ARROW_ASSIGN_OR_RAISE(auto scanner, scanner_builder->Finish());
ARROW_ASSIGN_OR_RAISE(auto table, scanner->ToTable());
std::cout << "Got " << table->num_rows() << " rows" << std::endl;
return arrow::Status::OK();
}
int main(int, char**) {
auto status = ScanDataset();
if (!status.ok()) {
std::cerr << status.message() << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
我們要感謝 Ivo Jimenez、Jeff LeFevre、Michael Sevilla 和 Noah Watkins 對此專案的貢獻。
這項工作部分由國家科學基金會 (National Science Foundation) 在合作協議 OAC-1836650、美國能源部 ASCR DE-NA0003525 (FWP 20-023266) 以及開源軟體研究中心 (cross.ucsc.edu) 的資助下完成。
更多資訊,請參閱以下論文和文章
- SkyhookDM:使用可程式化儲存在 Ceph 中進行資料處理。 (USENIX ;login: issue 2020 年夏季號,第 45 卷,第 2 期)
- SkyhookDM 現在是 Apache Arrow 的一部分了! (Medium)
- 邁向 Arrow 原生儲存系統。 (arXiv.org)