更快的 C++ Apache Parquet 效能,適用於 Apache Arrow 0.15 中的字典編碼字串資料
已發布 2019 年 9 月 5 日
作者 Wes McKinney (wesm)
我們一直在 Apache Parquet C++ 內部實作一系列最佳化,以提高 Arrow 欄狀二進位和字串資料的讀取和寫入效率(效能和記憶體使用量),並為 Arrow 的字典類型提供新的「原生」支援。這應該對 Parquet 檔案的 C++、MATLAB、Python、R 和 Ruby 介面的使用者產生重大影響。
這篇文章回顧了已完成的工作,並展示了 Arrow 0.12.1 與目前開發版本(即將作為 Arrow 0.15.0 發布)的基準測試比較。
工作摘要
最大且最複雜的最佳化之一,涉及將 Parquet 檔案內部字典編碼資料流編碼和解碼為 Arrow 的記憶體內字典編碼 DictionaryArray 表示法,以及從其編碼和解碼。字典編碼是 Parquet 中的一種壓縮策略,並且沒有正式的「字典」或「類別」類型。我將在下面更詳細地介紹這一點。
與這項工作相關的一些特定 JIRA 問題包括
- 向量化比較器以計算統計資訊 (PARQUET-1523)
- 直接將二進位資料讀取到字典建構器中 (ARROW-3769)
- 將 Parquet 的字典索引直接寫入字典建構器 (ARROW-3772)
- 直接將密集(非字典)Arrow 陣列寫入 Parquet 資料編碼器 (ARROW-6152)
- 直接將
arrow::DictionaryArray寫入 Parquet 欄位寫入器 (ARROW-3246) - 支援變更字典 (ARROW-3144)
- 內部 IO 最佳化和改進的原始
BYTE_ARRAY編碼效能 (ARROW-4398)
開發 Parquet C++ 程式庫的挑戰之一是,我們維護不涉及 Arrow 欄狀資料結構的低階讀取和寫入 API。因此,我們必須注意實作與 Arrow 相關的最佳化,而不會影響非 Arrow Parquet 使用者,其中包括 Clickhouse 和 Vertica 等資料庫系統。
背景:Parquet 檔案如何進行字典編碼
許多 Apache Arrow 的直接和間接使用者使用字典編碼來提高效能和記憶體使用率,適用於包含許多重複值的二進位或字串資料類型。MATLAB 或 pandas 使用者會將此稱為類別類型(請參閱 MATLAB 文件 或 pandas 文件),而在 R 中,此類編碼稱為 factor。在 Arrow C++ 程式庫和各種繫結中,我們具有 DictionaryArray 物件,用於表示記憶體中的此類資料。
例如,如下所示的陣列
['apple', 'orange', 'apple', NULL, 'orange', 'orange']
具有字典編碼形式
dictionary: ['apple', 'orange']
indices: [0, 1, 0, NULL, 1, 1]
Parquet 格式使用字典編碼來壓縮資料,並且適用於所有 Parquet 資料類型,而不僅僅是二進位或字串資料。Parquet 進一步使用位元組封裝和行程長度編碼 (RLE) 來壓縮字典索引,因此,如果您有如下所示的資料
['apple', 'apple', 'apple', 'apple', 'apple', 'apple', 'orange']
索引將像這樣編碼
[rle-run=(6, 0),
bit-packed-run=[1]]
rle-bitpacking 編碼的完整詳細資訊可在 Parquet 規格中找到。
在寫入 Parquet 檔案時,大多數實作將使用字典編碼來壓縮欄位,直到字典本身達到特定大小閾值(通常約為 1 MB)。在這一點上,欄位寫入器將「回退」到 PLAIN 編碼,其中值以「資料頁面」形式端對端寫入,然後通常使用 Snappy 或 Gzip 壓縮。請參閱以下粗略圖表

更快地讀取和寫入字典編碼資料
在讀取 Parquet 檔案時,字典編碼部分通常會實體化為其非字典編碼形式,導致二進位或字串值在記憶體中重複。因此,一個顯而易見(但並非微不足道)的最佳化是跳過此「密集」實體化。有幾個問題需要處理
- Parquet 檔案通常包含每個語義欄位的多個 ColumnChunk,並且每個 ColumnChunk 中的字典值可能不同
- 我們必須優雅地處理非字典編碼的「回退」部分
我們追求了幾種途徑來協助解決此問題
- 允許每個
DictionaryArray具有不同的字典(之前,字典是DictionaryType的一部分,這會導致問題) - 我們啟用了 Parquet 字典索引直接寫入 Arrow
DictionaryBuilder,而無需重新雜湊資料 - 在解碼 ColumnChunk 時,我們首先將字典值和索引附加到 Arrow
DictionaryBuilder中,當我們遇到「回退」部分時,我們使用雜湊表將這些值轉換為字典編碼形式 - 當從
DictionaryArray寫入 ColumnChunk 時,我們會覆寫「回退」邏輯,以便更有效率地讀回此類資料
所有這些結合在一起產生了一些出色的效能結果,我們將在下面詳細介紹。
我們實作的另一類最佳化是移除低階 Parquet 欄位資料編碼器和解碼器類別與 Arrow 欄狀資料結構之間的抽象層。這涉及
- 新增
ColumnWriter::WriteArrow和Encoder::Put方法,這些方法直接接受arrow::Array物件 - 新增
ByteArrayDecoder::DecodeArrow方法,以將二進位資料直接解碼為arrow::BinaryBuilder。
雖然這項工作帶來的效能提升不如字典編碼資料那麼顯著,但它們在實際應用中仍然有意義。
效能基準測試
我們執行了一些基準測試,比較了 Arrow 0.12.1 與目前的 master 分支。我們建構了兩種 Arrow 表格,每種表格包含 10 個欄位
- 「低基數」和「高基數」變體。「低基數」案例具有 1,000 個唯一的字串值,每個字串值為 32 位元組。「高基數」具有 100,000 個唯一值
- 「密集」(非字典)和「字典」變體
我們展示了單執行緒和多執行緒讀取效能。測試機器是使用 gcc 8.3.0 (在 Ubuntu 18.04 上) 的 Intel i9-9960X,具有 16 個實體核心和 32 個虛擬核心。所有時間測量均以秒為單位報告,但我們最感興趣的是展示相對效能。
首先,是寫入基準測試
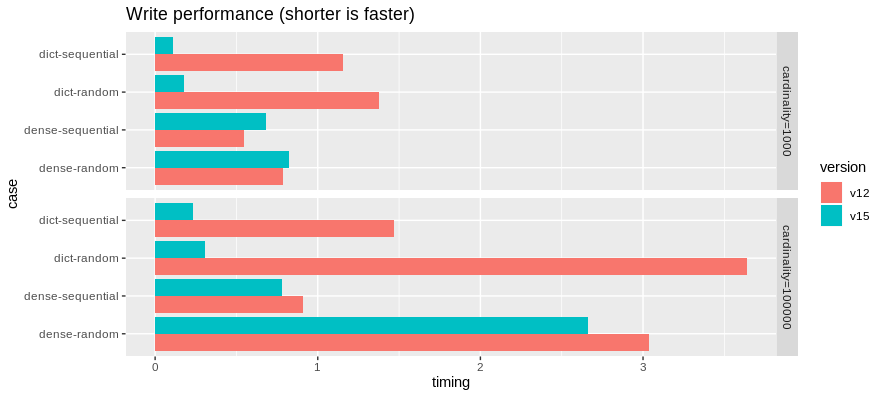
由於上述最佳化,寫入 DictionaryArray 的速度顯著加快。我們在寫入密集(非字典)二進位陣列方面取得了一些小的改進。
然後,是讀取基準測試
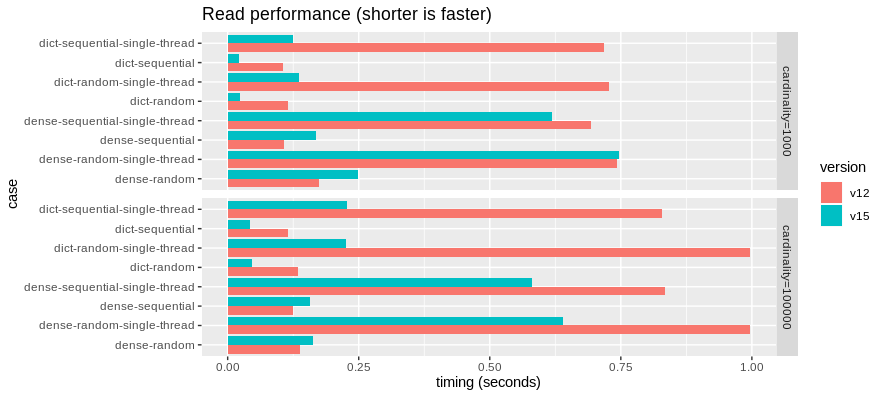
在這裡,類似地,直接讀取 DictionaryArray 的速度快了許多倍。
這些基準測試表明,密集二進位資料的平行讀取速度可能略有降低,但單執行緒讀取速度現在更快。我們可能需要進行一些效能分析,看看我們可以做些什麼來使讀取效能恢復正常。相對於字典讀取路徑,最佳化密集讀取路徑在這項工作中並不是太優先。
記憶體使用量改進
除了更快的效能外,以字典編碼形式讀取欄位還可以顯著減少記憶體使用量。
在上面的 dict-random 案例中,我們發現 master 分支在載入 152 MB 資料集時,峰值記憶體使用量為 405 MB RAM。在 v0.12.1 中,載入相同的 Parquet 檔案而不使用加速字典支援時,峰值記憶體使用量為 1.94 GB,而產生的非字典表格佔用 1.01 GB。
請注意,我們在 0.14.0 和 0.14.1 版本中存在記憶體過度使用錯誤,已在 ARROW-6060 中修復,因此,如果您遇到此錯誤,您將需要升級到 0.15.0,一旦它發布。
結論
未來我們可能還會追求許多與 Parquet 相關的最佳化,但這裡的最佳化可能對處理大量字串資料集的人們非常有幫助,無論是在效能還是記憶體使用量方面。如果您想討論這項開發工作,我們很樂意在我們的開發人員郵寄清單 dev@arrow.apache.org 上收到您的來信。